


CoDi: Unleashing the Power of Multimodal Generation with Infinite Possibilities
Harnessing CoDi and Emerging Technologies to Enhance User Experiences and Drive Innovation

Groundbreaking advancement in generative AI!
The introduction of Composable Diffusion (CoDi), a cutting-edge generative AI model, allows businesses and entrepreneurs to break free from the limitations of single modality generation and create immersive experiences by generating any combination of text, audio, image, and video simultaneously.
Introducing Composable Diffusion (CoDi), a cutting-edge foundation model that breaks free from the limitations of traditional multimodal generation.Unlike existing models that can only generate one modality from another, CoDi has the extraordinary ability to generate any combination of text, audio, image, and video simultaneously. This revolutionary advancement opens up a world of possibilities for businesses and creators seeking to enhance user experiences and break free from the constraints of single modality generation. The era of unrestricted multimodal generation has arrived!
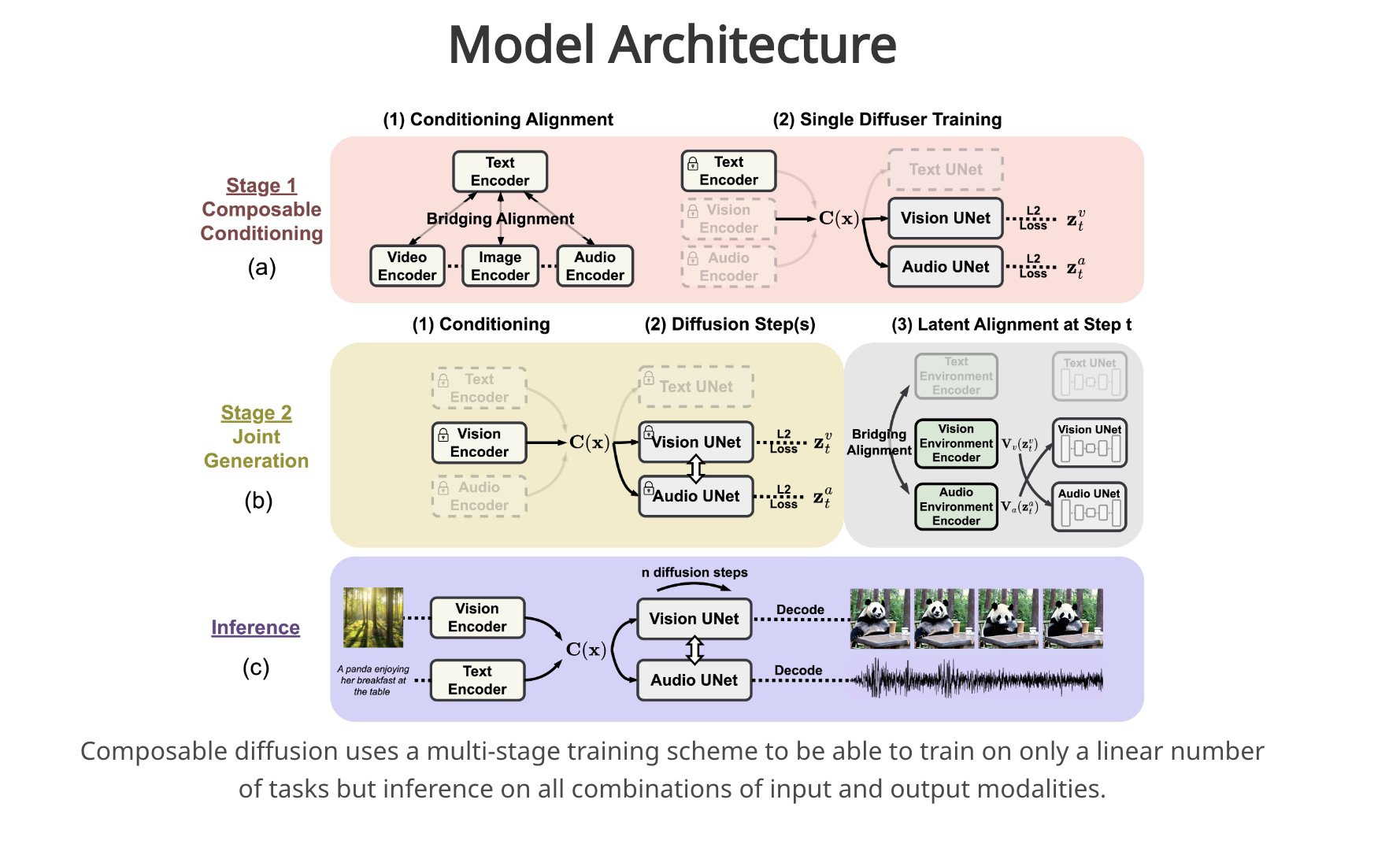
🔍 CoDi is a novel generative model capable of generating any combination of output modalities from any combination of input modalities, such as language, image, video, or audio.
🌐 Unlike existing AI systems, CoDi can generate multiple modalities in parallel and is not limited to a subset of modalities like text or image.
🔁 CoDi aligns modalities in both the input and output space, allowing it to condition on any input combination and generate any group of modalities, even if they are not present in the training data.
💡 CoDi employs a composable generation strategy, building a shared multimodal space through alignment in the diffusion process, enabling synchronized generation of intertwined modalities.
🚀 CoDi achieves strong joint-modality generation quality and outperforms or is on par with the state-of-the-art for single-modality synthesis.
Implications for Businesses and Entrepreneurs:
📈 CoDi's any-to-any generation capability has significant implications for businesses and entrepreneurs in various domains.
🌍 Businesses can leverage CoDi to create immersive and engaging experiences by generating coherent combinations of video, audio, and text in real-time.
💡 Entrepreneurs can explore new possibilities in content creation, advertising, virtual reality, and augmented reality by utilizing CoDi to generate diverse and interactive multimodal outputs.
🧪 CoDi's flexibility allows businesses to experiment with different combinations of modalities and adapt to evolving customer preferences and market trends.
💻 Entrepreneurs in the AI industry can leverage CoDi's architecture and techniques to develop their own multimodal generative models, catering to specific application domains.
Why does it matter?
Unrestricted Multimodal Generation: CoDi's unique ability to generate any combination of modalities simultaneously opens up new possibilities for businesses and creators seeking to enhance user experiences.
Enhanced User Experiences: Businesses can leverage CoDi to generate coherent combinations of video, audio, and text in real-time, creating immersive and engaging experiences for their users.
Diverse and Interactive Multimodal Outputs: Entrepreneurs can utilize CoDi to generate diverse and interactive multimodal outputs, exploring new possibilities in content creation, advertising, virtual reality, and augmented reality.
Flexibility for Customization: CoDi's architecture and techniques can be used by entrepreneurs in the AI industry to develop their own multimodal generative models, catering to specific application domains.
Strategic Recommendations:
To fully leverage the potential of multimodal generative models like CoDi, businesses and entrepreneurs should stay updated, explore relevant use cases, invest in diverse data collection, collaborate with AI experts, develop prototypes, and gather user feedback for continuous improvement.